流计算
流计算是指将业务系统产生的持续增长的动态数据进行实时的收集、清洗、统计、入库。DolphinDB内置的流计算框架支持流数据的发布、订阅、预处理、实时内存计算、复杂指标的滚动窗口计算等功能。
DolphinDB流计算框架采用发布-订阅-消费的模式。流数据首先注入流数据表中,通过流数据表来发布数据,数据节点、计算节点或者第三方应用可以通过DolphinDB脚本或API来订阅及消费流数据。
流数据表
流数据表是一种特殊的内存表,用以存储及发布流数据。流数据表支持同时读写,只能添加记录,不可修改或删除记录。
streamTable 函数可以创建流数据表。对于每一个发布端,通常会有多个会话中的多个订阅端同时订阅,因此必须使用 share 命令将流数据表共享后才可发布流数据。不被共享的流数据表无法发布流数据。
$ colName=["Name","Age"]
$ colType=["string","int"]
$ t = streamTable(100:10, colName, colType)
$ share t as st;
启用发布-订阅
使用DolphinDB的流计算功能前,需要进行环境配置。流计算需要配置两种节点:信息发布节点和信息订阅节点。一个信息发布节点可以同时向多个信息订阅节点传输数据,一个信息订阅节点也可以同时从多个信息发布节点订阅数据。一个节点可以既是发布节点,也是订阅节点。
信息发布节点必须配置maxPubConnections参数>0,表示信息发布节点最多可连接多少订阅节点。信息订阅节点必须配置subPort参数。如果有多个信息订阅节点,那么应当为每个订阅节点都配置不同的subPort。
我们可以通过以下3种方式进行配置:
下面的例子中。local8080为信息发布节点,local8081为信息订阅节点。
1. 通过Web集群管理界面的Nodes Config:
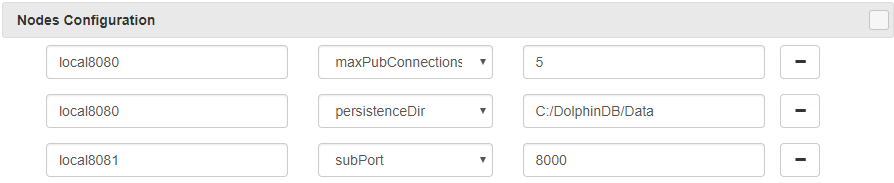
如果需要将流数据表持久化,需要指定persistenceDir。修改节点配置信息后,需要重启数据节点/计算节点。
2. 使用命令行启动数据节点/计算节点时启动发布-订阅
使用参数maxPubConnections配置信息发布节点:
$ dolphindb -home C:/DolphinDB/clusters/inst1 -logFile inst1.log -localSite localhost:8080:local8080 -maxPubConnections 5 -persistenceDir C:/DolphinDB/Data
使用参数subPort配置信息订阅节点:
$ dolphindb -home C:/DolphinDB/clusters/inst2 -logFile inst2.log -localSite localhost:8081:local8081 -subPort 8000
端口8081和8000在同一节点上。信息发布节点把流数据推送带端口8000,而端口8081用作其他用途。
3. 在配置文件cluster.cfg中添加以下信息:
$ local8080.maxPubConnections=5
$ local8080.persistenceDir=C:/DolphinDB/Data
$ local8081.subPort=8000
示例
下面是关于流计算的例子。在本例中,集群有两个节点:DFS_NODE1和DFS_NODE2。我们需要在 cluster.cfg 中指定maxPubConnections和subPort参数来启动发布/订阅功能。例如:
$ maxPubConnections=32
$ DFS_NODE1.subPort=9010
$ DFS_NODE2.subPort=9011
$ DFS_NODE1.persistenceDir=C:/DolphinDB/Data
在DFS_NODE1上执行以下脚本:
1.创建一个共享的流数据表trades_stream,并以同步模式保存。此时,表trades_stream有0行记录。
$ n=20000000
$ colNames = `time`sym`qty`price
$ colTypes = [TIME,SYMBOL,INT,DOUBLE]
$ enableTableShareAndPersistence(streamTable(n:0, colNames, colTypes), "trades_stream", false, true, n)
$ go;
2.创建一个分布式的表trades。此时,表trades有0行记录。
$ if(existsDatabase("dfs://STREAM_TEST")){
$ dropDatabase("dfs://STREAM_TEST")
$ }
$ dbDate = database("", VALUE, temporalAdd(date(today()),0..30,'d'))
$ dbSym= database("", RANGE, string('A'..'Z') join "ZZZZ")
$ db = database("dfs://STREAM_TEST", COMPO, [dbDate, dbSym])
$ colNames1 = `date`time`sym`qty`price
$ colTypes1 = [DATE,TIME,SYMBOL,INT,DOUBLE]
$ trades = db.createPartitionedTable(table(1:0, colNames1, colTypes1), "trades", `date`sym)
3.创建表trades_stream的本地订阅。使用saveTradesToDFS函数把表trades_stream的流数据和今天的日期保存至表trades。
$ def saveTradesToDFS(mutable dfsTrades, msg): dfsTrades.append!(select today() as date,* from msg)
$ subscribeTable(tableName="trades_stream", actionName="trades", offset=0, handler=saveTradesToDFS{trades}, msgAsTable=true, batchSize=100000, throttle=60);
4.创建表trades_stream的另一个本地订阅。使用每分钟的流数据计算成交量加权平均价格(vwap),并以异步模式把结果保存至共享的流数据表vwap_stream中。
$ n=1000000
$ tmpTrades = table(n:0, colNames, colTypes)
$ lastMinute = [00:00:00.000]
$ colNames2 = `time`sym`vwap
$ colTypes2 = [MINUTE,SYMBOL,DOUBLE]
$ share streamTable(n:0, colNames2, colTypes2) as vwap_stream
$ enableTablePersistence(vwap_stream, true)
$ def calcVwap(mutable vwap, mutable tmpTrades, mutable lastMinute, msg){
$ tmpTrades.append!(msg)
$ curMinute = time(msg.time.last().minute()*60000l)
$ t = select wavg(price, qty) as vwap from tmpTrades where time < curMinute, time >= lastMinute[0] group by time.minute(), sym
$ if(t.size() == 0) return
$ vwap.append!(t)
$ t = select * from tmpTrades where time >= curMinute
$ tmpTrades.clear!()
$ lastMinute[0] = curMinute
$ if(t.size() > 0) tmpTrades.append!(t)
$ }
$ subscribeTable(tableName="trades_stream", actionName="vwap", offset=0, handler=calcVwap{vwap_stream, tmpTrades, lastMinute}, msgAsTable=true, batchSize=100000, throttle=60);
在DFS_NODE2上执行以下脚本,创建表trades_stream的远程订阅,并以异步模式把流数据保存至表trades_stream_slave中。
$ n=20000000
$ colNames = `time`sym`qty`price
$ colTypes = [TIME,SYMBOL,INT,DOUBLE]
$ share streamTable(n:0, colNames, colTypes) as trades_stream_slave
$ enableTablePersistence(table=trades_stream_slave, cacheSize=n)
$ go;
$ subscribeTable(server="DFS_NODE1", tableName="trades_stream", actionName="slave", offset=0, handler=trades_stream_slave);
在DFS_NODE1上执行以下脚本,模拟3支股票在10分钟内的流数据。每支股票每分钟生成2,000,000条记录。每分钟的数据被插入到流数据表trades_stream的600个数据块中。每两个数据块有100毫秒的时间间隔。
$ n=10
$ ticks = 2000000
$ rows = ticks*3
$ startMinute = 09:30:00.000
$ blocks=600
$ for(x in 0:n){
$ time = startMinute + x*60000 + rand(60000, rows)
$ indices = isort(time)
$ time = time[indices]
$ sym = array(SYMBOL,0,rows).append!(take(`IBM,ticks)).append!(take(`MSFT,ticks)).append!(take(`GOOG,ticks))[indices]
$ price = array(DOUBLE,0,rows).append!(norm(153,1,ticks)).append!(norm(91,1,ticks)).append!(norm(1106,20,ticks))[indices]
$ indices = NULL
$ blockSize = rows / blocks
$ for(y in 0:blocks){
$ range =pair(y * blockSize, (y+1)* blockSize)
$ insert into trades_stream values(subarray(time,range), subarray(sym,range), 10+ rand(100, blockSize), subarray(price,range))
$ sleep(100)
$ }
$ blockSize = rows % blocks
$ if(blockSize > 0){
$ range =pair(rows - blockSize, rows)
$ insert into trades_stream values(subarray(time,range), subarray(sym,range), 10+ rand(100, blockSize), subarray(price,range))
$ }
$ }
在DFS_NODE1上执行以下脚本来检查结果:
$ trades=loadTable("dfs://STREAM_TEST", `trades)
$ select count(*) from trades
结果预期是有60,000,000条记录。
$ select * from vwap_stream
表vwap_stream预期是有27条记录。
在DFS_NODE2上执行以下脚本:
$ select count(*) from trades_stream_slave
预期可见的结果的记录少于60,000,000条,因为部分记录已经保存至磁盘中。
流数据持久化
默认情况下,流数据表把所有数据都保存在内存。随着时间的推移,流数据累积到一定程度会出现内存不足的情况。DolphinDB提供了流数据持久化的功能,可将内存中的流数据以异步或同步的方式保存至磁盘中。流数据持久化具有以下优点:
1. 避免内存不足。 2. 流数据的备份和恢复。当节点宕机重启时,持久化的流数据会自动载入。 3. 流数据持久化的一个重要目的是可以从任意位置开始重新订阅数据。
要持久化流数据表,在发布节点首先需要设置持久化路径参数persistenceDir,然后执行 enableTableShareAndPersistence 命令。
enableTableShareAndPersistence命令的语法:enableTableShareAndPersistence(table, tableName, [asynWrite=true], [compress=true], [cacheSize=-1], [retentionMinutes=1440], [flushMode=0])
enableTableShareAndPersistence函数的参数设定会影响流数据系统的性能:
1. asynWrite表示持久化是否采用异步的方式。采用异步持久化的方式可以提高系统的吞吐量,但是代价是如果节点宕机,可能会造成最后几条数据丢失。如果应用场景对流数据的一致性要求极高,建议采用同步的方式,这样数据只有在持久化完成后才会进入发布队列。 2. compress表示持久化到磁盘的数据是否压缩。数据压缩可以减少磁盘写入量和空间占用。 3. cacheSize表示流数据表在内存中最多保留多少行。 4. retentionMinutes表示流数据日志的保留时间。 5. flushMode表示流数据是否立即写到磁盘上。默认值0,表示流数据首先写入操作系统缓存,不立刻写入到磁盘上。如果flushMode=1,流数据会立刻写入到磁盘上。
getPersistenceMeta 函数可以查看持久化的流数据表的信息。 clearTablePersistence 函数可以删除持久化的数据。 disableTablePersistence 函数可以停止流数据表持久化。
自动重订阅
DolphinDB的流数据订阅提供了自动重连的功能。如果要启用自动重连,发布端必须对流数据持久化。当reconnect参数设为true时,订阅端会记录流数据的offset,连接中断时订阅端会从offset开始重新订阅。如果订阅端崩溃或者发布端没有对流数据持久化,订阅端无法自动重连。
发布端数据过滤
发布端可以对数据进行过滤,只发布符合条件的数据。首先,使用 setStreamTableFilterColumn 函数指定发布表的过滤列,然后指定subscribeTable函数的filter参数。filter是一个向量。发布表过滤列只有在filter中的数据才会发布到订阅端,不在filter中的数据不会发布。目前仅支持对一个列的数据进行过滤。在发布端进行数据过滤可以减少网络流量。例如,发布端上的流数据表trades只向该订阅节点发布symbol为IBM和GOOG的数据:
$ share streamTable(10000:0,`time`symbol`price, [TIMESTAMP,SYMBOL,INT]) as trades
$ setStreamTableFilterColumn(trades, `symbol)
$ trades_slave=table(10000:0,`time`symbol`price, [TIMESTAMP,SYMBOL,INT])
$ filter=symbol(`IBM`GOOG)
$ subscribeTable(tableName=`trades, actionName=`trades_slave, handler=append!{trades_slave}, msgAsTable=true, filter=filter);
取消订阅
每一个订阅都有一个订阅主题topic作为唯一标识。如果订阅时topic已经存在,那么会订阅失败。这时需要通过 unsubscribeTable 函数取消订阅才能再次订阅。例如:
$ unsubscribeTable(tableName="trades_stream", actionName="trades");